Java集合
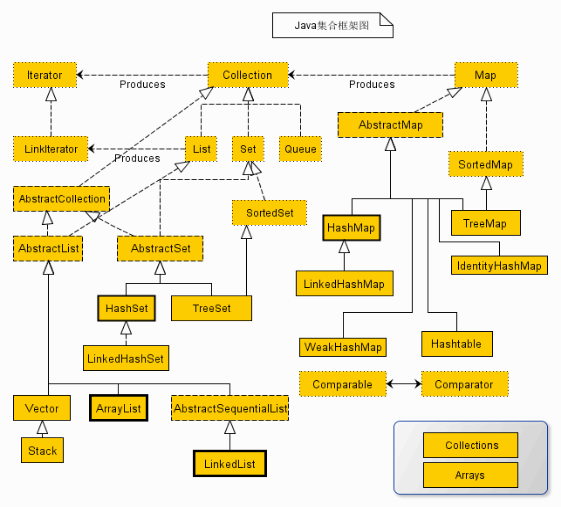
重要的接口
List(有序、可重复)
List里存放的对象是有序的,同时也是可以重复的,List关注的是索引,拥有一系列和索引相关的方法,查询速度快。因为往list集合里插入或删除数据时,会伴随着后面数据的移动,所有插入删除数据速度慢。Set(无序、不能重复)
Set里存放的对象是无序,不能重复的,集合中的对象不按特定的方式排序,只是简单地把对象加入集合中。Map(键值对、键唯一、值不唯一)
Map集合中存储的是键值对,键不能重复,值可以重复。根据键得到值,对map集合遍历时先得到键的set集合,对set集合进行遍历,得到相应的值。
对比如下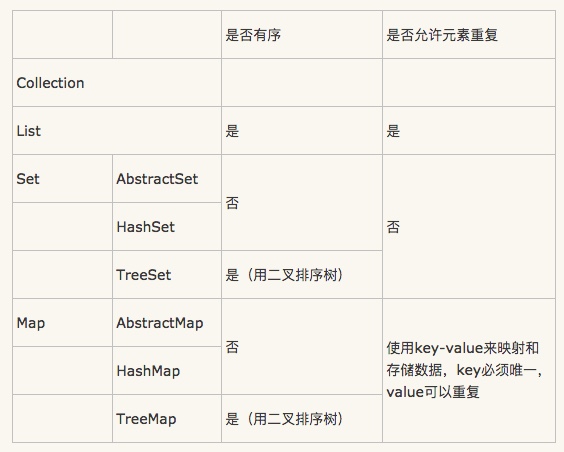
List,允许重复元素
ArrayList:基于数组实现
Vector:基于数组实现,方法都是同步的(Synchronized),是线程安全的
LinkedList:基于链表实现,两者都有序
Set,不允许有重复值
HashSet基于HashMap实现,只不过Key-Value里面的value都是同一个object,因为是基于hashmap(散列表)实现,所以自然是无序的
TreeSet基于TreeMap实现,只不过Key-Value里面的value都是同一个object,因为是基于TreeMap(红黑树)实现,所以自然是有序的
Map,键值对,key唯一,value可重复
HashMap:最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。因为键对象不可以重复,所以HashMap最多只允许一条记录的键为Null,允许多条记录的值为Null,是非同步的。
- resize时为什么要乘以2,或者说为什么capacity是2的次幂
- 对hashcode取模的时候用的位操作符&,hashcode & length-1,如果不是2的次幂,那么length-1的二进制表示中很有可能有0位,那么位与运算后,这个位置永远为0,hash冲突概率增加
- resize时乘以2的话,在取模的时候,相当于比原来多了一位,在重新寻址的时候,只要看多出来的一位是0还是1即可,是0的话位置不变,是1的话新的索引位置就是老索引加上老的长度c
Hashtable:与HashMap类似,也是散列表实现,是HashMap的线程安全版,它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢,它继承自Dictionary类,不同的是它不允许记录的键或者值为null,同时效率较低。
TreeMap:基于红黑树实现,实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序(自然顺序),也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。不允许key值为空,因为无法比较,非同步的
LinkedHashMap:保存了记录的插入顺序,在用Iteraor遍历LinkedHashMap时,先得到的记录肯定是先插入的,在遍历的时候会比HashMap慢,有HashMap的全部特性。这是因为LinkedHashMap中的Node有before和after两个引用,分别指向前一个和后一个节点
ConcurrentHashMap:线程安全,并且锁分离。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hash table,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。java1.7和1.8的实现有很大区别,见https://www.cnblogs.com/study-everyday/p/6430462.html
- resize时为什么要乘以2,或者说为什么capacity是2的次幂
- hashmap在java1.7和1.8的区别
- JDK1.7中
使用一个Entry数组来存储数据,用key的hashcode取模来决定key会被放到数组里的位置,如果hashcode相同,或者hashcode取模后的结果相同(hash collision),那么这些key会被定位到Entry数组的同一个格子里,这些key会形成一个链表。
在hashcode特别差的情况下,比方说所有key的hashcode都相同,这个链表可能会很长,那么put/get操作都可能需要遍历这个链表,也就是说时间复杂度在最差情况下会退化到O(n)。 - JDK1.8中
使用一个Node数组来存储数据,但这个Node可能是链表结构,也可能是红黑树结构,如果插入的key的hashcode相同,那么这些key也会被定位到Node数组的同一个格子里。如果同一个格子里的key不超过8个,使用链表结构存储。如果超过了8个,那么会调用treeifyBin函数,将链表转换为红黑树。那么即使hashcode完全相同,由于红黑树的特点,查找某个特定元素,也只需要O(log n)的开销。也就是说put/get的操作的时间复杂度最差只有O(log n)。
听起来挺不错,但是真正想要利用JDK1.8的好处,有一个限制:key的对象,必须正确的实现了Compare接口,如果没有实现Compare接口,或者实现得不正确(比方说所有Compare方法都返回0)。那JDK1.8的HashMap其实还是慢于JDK1.7的。